
Minggu, 13 Juni 2010
BAG XI. Program Simplis
Hal-hal yang perlu diperhatikan dalam menggunakan Simplis adalah :
- Huruf besar maupun huruf kecil bias saling dugunakan
- Tanda seru (!) atau garis miring asterisk (/*) digunakan untuk menunjukkan bahwa apa saja dibelakangnya pada garis tersebut dianggap sebagai komentar
- Sebuah physical line diakhiri dengan sebuah karakter RETURN dan atau LINE FEED
- SIMPLIS command line diakhiri dengan sebuah karakter RETURN dan atau LINE FEED atau sebuah semicolon ( ; )
Menyiapkan input file atau perintah (Program/Bahasa SIMPLIS)
Buka program LISREL, kemudian klik File dan klik New. Akan muncul tampilan berikut :

Kemudian klik SIMPLIS Project, dan klik OK. Akan muncul kotak dialog Save As.
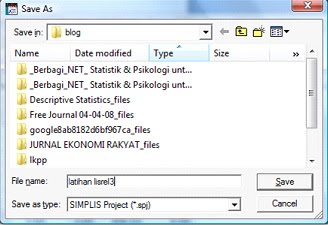
Pada Save in, pilih folder tempat data disimpan. Pada Save of Type pilih SIMPLIS Project (*.spj). Pada File Name pilih nama file. Kemudian klik Save. Akan muncul tampilan kosong berikut tempat untuk menginput/menulis perintah

Struktur Penulisan Perintah Pada Program Simplis
Syntax dan aturan-aturan yang sering digunakan dalam input file SIMPLIS sebagai berikut: (syntax lainnya selain yang diberikan di bawah ini, akan diberikan bersamaan dengan contoh aplikasi pada seri-seri tulisan berikutnya mengenai LISREL).
1. Baris Judul
Baris pertama pada input file dapat digunakan sebagai baris judul. Setiap keterangan pada baris pertama akan diperlakukan sebagai baris judul kecuali LISREL menemukan dua hal berikut:
· Baris yang dimulai dengan kata Observed Variables atau Labels yang merupakan baris perintah pertama dalam input file SIMPLIS
· Baris yang dua karakter (huruf) pertamanya dimulai dengan DA, Da, dA atau da, yang merupakan baris perintah pertama dalam input file SIMPLIS
2. Variabel Observed
Setelah baris judul, baris selanjutnya adalah observed variables, yang merupakan variabel yang memiliki nilai pada input data.
· Baris ini harus dilakukan jika input data adalah matriks kovarians atau matriks korelasi atau data mentah yang disimpan dalam file text.
· Baris ini tidak diharuskan jika input data menggunakan data mentah yang disimpan dalam program PRELIS.
Penulisan observed variables dengan memberikan spasi antar variabel. Contoh: Observed Variables X1 X2 X3 Y1 Y2
3. Data
Setelah baris observed variables, baris selanjutnya adalah penjelasan unuk input data. Dalam LISREL input data dapat berupa data mentah, Matriks kovarians, Matriks kovarias dan means, Matriks korelasi,Matriks korelasi dan standar deviasi, Matriks korelasi, standar deviasi dan means. Pada seluruh macam format input data tersebut, asymptotic covariance matrix juga dapat ditambahkan pada input data.
Untuk membaca data, perintahnya adalah sebagai berikut:
· Untuk Data mentah
Raw Data from file ‘nama file’
· Matriks kovarians
Covariance Matrix from file ‘nama file’
· Matriks kovarians dan means
Covariance Matrix from file ‘nama file’
Means from file ‘nama file’
· Matriks korelasi
Correlations Matrix from file ‘nama file’
· Matriks korelasi dan standar deviasi
Correlations Matrix from file ‘nama file’
Standard Deviations from file ‘nama file’
· Matriks korelasi, standar deviasi dan means
Correlations Matrix from file ‘nama file’
Standard Deviations from file ‘nama file’
Means from file ‘nama file’
· Asymptotic Covariance Matrix
Asymptotic Covariance Matrix from file ‘nama file’
· Asymptotic Variances Matrix
Asymptotic Variances Matrix from file ‘nama file’
4. Ukuran Sampel
Ukuran sampel perlu dituliskan jika input data bukan berupa data mentah. Contoh penulisannya sebagai berikut: Sample size = 113
5. Variabel Laten atau Unobserved
Untuk menuliskan nama variabel laten dapat menggunakan Latent Variables atau Unobserved Variables. Nama variabel laten tidak boleh sama dengan variabel observed. Contoh penulisan:
Latent Variables: komitmen kepuasan kinerja
2. Relationships (hubungan)
Setelah baris variabel laten, baris selanjutnya adalah baris hubungan. Judul untuk baris ini dapat ditulis sebagai Relationships, Relations atau Equations. Judul juga boleh tidak dituliskan.
Penulisan hubungan bisa menggunakan persamaan (tanda =) berikut:
Variabel dependen = variabel independen
Indikator = variabel laten
Penulisan hubungan juga bisa dilakukan dengan menggunakan path (jalur) berikut:
Variabel independen → variabel dependen
Variabel laten → indikator
Baik dengan menggunakan persamaan maupun menggunakan path, penulisan variabel dapat dilakukan secara simultan (beberapa/seluruh variabel dituliskan secara bersamaan). Berkaitan dengan ini, penulisannya dapat dilakukan dengan versi pendek atau versi panjang. Contoh:

3. LISREL Output
Output LISREL bisa dihasilkan dalam format SIMPLIS atau format LISREL. Pada format SIMPLIS, model diestimasi berdasarkan bentuk persamaan, sedangkan pada format LISREL, model disajikan dalam bentuk matriks. Format SIMPLIS diperoleh secara default, sedangkan format LISREL dapat diperoleh dengan menuliskan perintah pada file input sebagai berikut: LISREL Output
Jika hal-hal lainnya tidak dituliskan dalam baris LISREL Output, maka informasi yang disajikan akan sama dengan output SIMPLIS. Tetapi kita juga bisa memberikan informasi tambahan dengan menuliskan kata-kata kunci sebagai berikut:
LISREL Output: SS SC EF SE VA MR FS PC PT
SS : menghasilkan standardized solution
SC : menyajikan seluruhnya standardized solution
EF : menyajikan pengaruh langsung dan tidak langsung (komposisi pengaruh)
VA : menyajikan varians dan kovarians
MR : sama dengan RS dan VA
FS : menghasilkan nilai faktor regresi
PC : menyajikan korelasi antara estimasi parameter
PT : menyajikan informasi-informasi teknis
4. End of Problem
Untuk menunjukkan seluruh persamaan telah dituliskan, maka tuliskan baris: End of Problem. Pada multi sampel, End of Problem dituliskan pada akhir kelompok, tidak pada masing-masing kelompok
BAG VIII. Path Analysis (Analisis Jalur)
Analisis jalur digunakan untuk menelaah hubungan antara model kausal yang telah dirumuskan peneliti atas dasar pertimbangan teoritis dan pengetahuan tertentu. Suatu diagram jalur akan membantu di dalam menganalisis dan menginterpretasiakan hubunganyang dihipotesiskan.
Ada berbagai model hubungan yang dapat dibangun dari variabel penelitian yang sama, tergantung bagaimana hipotesis yang disusun peneliti mengenai hubungan antara variabel-variabel penelitian.

Cara melakukan analisis jalur adalah melalui Structural Equation Model (SEM), untuk menguji berbagai model hubungan yang ada, baik tanpa memperhitungkan ataupun dengan memperhitungkan besarnya kesalahan menggunakan program LISREL (Linear Structural Relationship) yang dikembangkan oleh Jöreskog dan Sorbom.
Dalam pengujian model dengan metode SEM, variabel yang diletakkan paling kiri disebut variabel eksogen, sedangkan variabel yang diletakkan paling kanan disebut variabel endogen. Adapun variabel yang menjadi variabel perantara dapat menjadi variabel eksogen dan juga endogen tergantung bagaimana hubungan diantara variabel-variabel tersebut.
Dalam contoh model b dan c di atas, variabel minat orang tua merupakan variabel eksogen, variabel prestasi akademik merupakan variabel endogen. Adapun variabel minat anak menjadi variabel endogen dari minat orang tua, dan juga variabel eksogen untuk prestasi akademik.
Dalam SEM, ada notasi yang digunakan untuk menggambarkan variabel-variabel penelitian dan hubungan diantara variabel.
ξ (ksi): variabel laten eksogen
η (eta): variabel laten endogen
γ (gamma): hubungan langsung variabel eksogen terhadap variabel endogen
β (beta): hubungan langsung antara variabel endogen terhadap variabel endogen
Notasi dalam model penelitian

Dalam output LISREL untuk uji model penelitian, ada 3 nilai yang dikeluarkan, yaitu:
• Nilai pada baris pertama menunjukkan besarnya hubungan variabel yang diteliti
• Nilai pada baris kedua menunjukkan besarnya standard error
• Nilai pada baris ketiga menunjukkan nilai t
--> Nilai kritis untuk t adalah ±1,96 (los 0,05), ±2,62 (los 0,01) dan ±3,37 (los 0,001)
--> Nilai t yang lebih besar dari nilai kritis menunjukkan bahwa hubungan antar variabel adalah signifikan
Persamaan Analisis Jalur dan SEM :
• Keduanya berkenan dengan model konstruksi
• Pendugaan parameter (koefisien) model dilakukan berdasarkan data sampel
• Pengujian kesesuaian model dilakukan dengan cara membandingkan matriks kovarians hasil dugaan dengan matrik kovarians data observasi.
Perbedaan Analisis Jalur dan SEM :
• Analisis Jalur hanya berkenan dengan pengujian kausal antar variabel, dan tidak dapat untuk memeriksa validitas dan reliabilitas pengukuran variabel laten berdasarkan variabel manifest, sedangkan SEM dapat digunakan untuk keduanya.
• SEM dapat diterapkan baik pada model rekursif ataupun pada model resiprokal, sedangkan Analisi Jalur hanya diterapkan pada model yang berhubungan kausal satu arah dan memenuhi model rekursif.
• Pada Analisis Jalur pendugaan parameter dilakuakn secara parsial untuk setiap persamaan yang membentuk model strukturalnya, sedangkan dalam SEM pendugaan parameter dilakukan secara serentak untuk seluruh parameter.
• Data input pada Analisis Jalur adalah data baku (standardized), sedangkan pada SEM bias data mentah atau normal baku.
• Output Analisis Jalur hanya factor determinan, sedangkan output SEM selain factor determinan juga model structural dan pengukuran.
BAG VII. Confirmatory Factor Analysis (CFA)
Analisis faktor atau CFA ini sedikit berbeda dengan analisis faktor yang digunakan pada statistik/multivariat (yang dikenal dengan Exploratory Factor Analysis atau EFA). Pada EFA model rinci yang menunjukkan hubungan antara variabel laten dengan variabel teramati tidak dispesifikasikan terlebih dahulu. Selain itu pada CFA jumlah variabel laten tidak ditentukan sebelum analisis dilakukan, dan semua variabel laten diasumsikan mempengaruhi semua variabel teramati. Sebaliknya pada CFA model dibentuk terlebih dahulu, jumlah variabel laten ditentukan oleh analis, dan pengaruh suatu variabel laten terhadap variabel teramati ditentukan terlebih dahulu.
Bentuk-bentuk measurement model adalah sebagai berikut :
• Measurement model untuk variabel independen
Peneliti dapat membuat confirmatory factor analysis terhadap variabel-variabel yang direncanakan akan diperlukan sebagai indikator dari variabel laten independen. Variabel observasi ini yang disebut variabel indikator atau dimensi harus dibangun berdasarkanpijakan teoritis yang cukup, serta justifikasi teoritis bahwa ia dapat dipertimbangkan sebagai indikator variabel laten independen.
• Measurement model untuk variabel laten dependen
Seperti variabel laten independen, confirmatory factor analysis hanya dapat dilakukan berdasarkan justifikasi teori yang cukup. Justifikasi dibutuhkan juga untuk memberikan perlakuan atas sebuah variabel sebagai variabel dependen dalam sebuah hubungan kausalitas yang akan dianalisis.
BAG VI. Prosedur SEM
1. Spesifikasi model (Model Specification)
Spesifikasi model dilakukan terhadap permasalahan yang diteliti. Spesifikasi model secara garis besar dijalankan dengan menspesifikasi model pengukuran serta menspesifikasi model structural.
Spesifikasi model pengukuran meliputi aktivitas mendefinisikan variable-variabel laten, mendefinisikan variabel-variabel teramati, dan mendefinisikan hubungan antara variable laten dengan variabel-variabel teramati.
Spesifikasi model structural dilakukan dengan mendefinisikan hubungan kausal diantara variabel-variabel laten. Tahapan selanjutnya (optional) adalah menetapkan gambaran path diagram model hybrid yang merupakan kombinasi model pengukuran dan struktural.
2. Identifikasi (Identification)
Tahap identifikasi bertujuan untuk menjaga agar model yang dispesifikasikan bukan model yang under-identified atau unidentified. Terdapat tiga kemungkinan identifikasi dalam persamaan simultan, yaitu under-identified, just-identified atau over-identified.
Under-identified model adalah model dimana jumlah parameter yang diestimasi lebih besar dari jumlah data yng diketahui. Pada kondisi under-identified model yang dispesifikasikan tidak memiliki penjelasan yang unik.
Just-identified model adalah model dimana jumlah parameter yang diestimasi sama dengan data yang diketahui. Pada kondisi just-identified, model yang dispesifikasikan hanya memiliki satu penyelesaian.
Over-identified model adalah model dimana jumlah parameter yang diestimasi lebih kecil dari jumlah data yang diketahui. Pada kondisi over-identified, penyelesaian model diperoleh melalui proses estimasi iterative. Penyelesaian yang diperoleh biasanya merupakan nilai-nilai yang konvergen ke nilai-nilai yang stabil.
3. Estimasi (Estimation)
Estimasi terhadap model dapat dilakukan dengan menggunakan salah satu metode estimasi yang tersedia, sebagai berikut :
• Instrumental Variable (IV)
• Two Stage Least Square (TSLS)
• Unweighted Least Squares (ULS)
• Generalized Least Squares (GLS)
• Maximum Likelihood (ML)
• Generally Weighted Least Squares (WLS)
• Diagonally Weighted Least Squares (DWLS)
Metode yang paling sering digunakan adalah Maximum Likelihood dan Weighted Least Squares.
4. Uji Kecocokan (Testing Fit)
Bertujuan untuk mengevaluasi derajat kecocokan atau Goodnes of Fit (GOF) antara data dan model. Menurut Heir et al. (1995) evaluasi terhadap GOF model dilakukan melalui beberapa tingkatan, yaitu :
• Kecocokan seluruh model (overall model fit)
• Kecocokan model pengukuran (measurement model fit)
• Kecocokan model struktural (structural model fit)
5. Respesifikasi (Re-specification)
Tahapan ini ditujukan untuk melakukan spesifikasi ulang terhadap model untuk memperoleh derajat kecocokan yang lebih baik. Respesifikasi ini sangat bergantung kepada strategi pemodelan yang dipilih. Dalam SEM tersedia 3 strategi pemodelan yang dapat dipilih (Joreskog dan Sorbom 1993, Heir et. al. 1995), yaitu :
• Strictly Confirmatory atau Confirmatory Modelling Strategy.
Pengujian dilakukan untuk mengahasilkan penerimaan atau penolakan terhadap model tersebut sebagaimana kriteria dari hipotesis nol. Model dinyatakan bagus bila mampu merepresentasikan data empiris. Tidak ada respesifikasi model dalam strategi ini.
• Alternative (Competing) Models atau Competing Model Strategy.
Beberapa model alternative dispesifikasikan dan dipilih salah satu yang paling sesuai. Respesifikasi hanya diperlukan jika model-model alternative dikembangkan dari model-model yang ada.
• Model Generating atau Model Development Strategy
Dimulai dengan spesifikasi suatu model awal, dilanjutkan dengan pengumpulan data empiris. Selanjutnya dilakukan analisi dan pengujian data. Jika tingkat kecocokan kurang baik, maka model dimodifikasi dan diuji kembali dengan data yang sama. Respesifikasi model diperlukan jika modelnya tidak memiliki kemampuan yang diharapkan.
Proses respesifikasi dilakukan berdasarkan theory driven atau data driven, meskipun respesifikasi berdasarkan theory driven lebih dianjurkan. Model ini merupakan strategi yang paling banyak digunakan dibandingkan kedua strategi diatas lainnya.